 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Information Structural Approach to Spoken Language Generation
Jul 03, 1996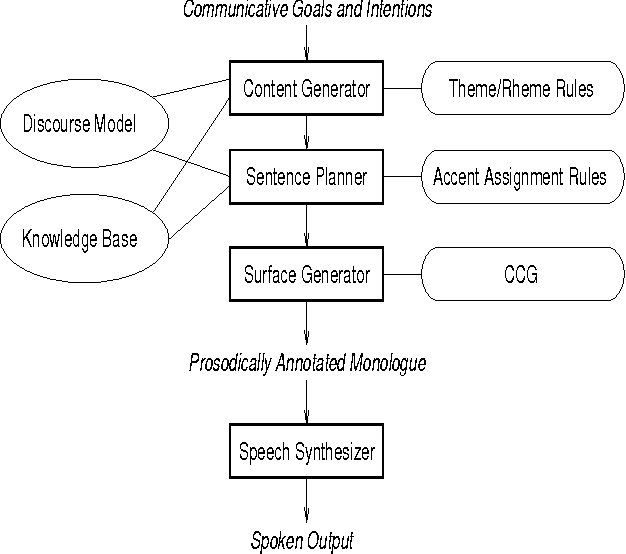
This paper presents an architecture for the generation of spoken monologues with contextually appropriate intonation. A two-tiered information structure representation is used in the high-level content planning and sentence planning stages of generation to produce efficient, coherent speech that makes certain discourse relationships, such as explicit contrasts, appropriately salient. The system is able to produce appropriate intonational patterns that cannot be generated by other systems which rely solely on word class and given/new distinctions.
Specifying Intonation from Context for Speech Synthesis
Jul 18, 1994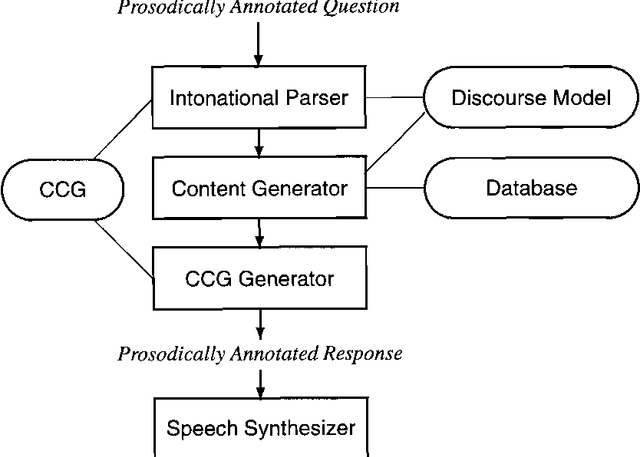
This paper presents a theory and a computational implementation for generating prosodically appropriate synthetic speech in response to database queries. Proper distinctions of contrast and emphasis are expressed in an intonation contour that is synthesized by rule under the control of a grammar, a discourse model, and a knowledge base. The theory is based on Combinatory Categorial Grammar, a formalism which easily integrates the notions of syntactic constituency, semantics, prosodic phrasing and information structure. Results from our current implementation demonstrate the system's ability to generate a variety of intonational possibilities for a given sentence depending on the discourse context.